

大模型部署之后能力还可以持续提升吗?
如果去问AI开发者这个问题,在过去,答案大多是否定的。传统的大模型在出厂那一刻,其智力水平就几乎定型了。即便在实际应用中遇到了未见过的新问题,或者被用户反馈指出错误,模型也很难像人类一样,在下一次尝试时立刻吸取教训。这正是当前大语言模型面临的尴尬现状。
在现有的主流范式下,AI模型性能的提升高度依赖于离线训练,要么是昂贵的人工标注,要么是预先构建的模拟环境。一旦模型部署到真实世界,它与用户的真实环境之间的海量交互经验往往不会被直接使用。
为了解决这一问题,微软亚洲研究院提出了全新的在线经验学习(Online Experiential Learning, OEL)框架 。这一框架让AI模型具备了边做边学的能力,能够从真实的交互经验中自我进化,开启了从静态模型向动态智能体转化的新篇章。
Online Experiential Learning for Language Models
论文链接:https://arxiv.org/abs/2603.16856 (opens in new tab)
代码链接:https://aka.ms/oel-code (opens in new tab)
大模型的困境:为什么现在的AI不会从经验中学习?
当前主流的大语言模型优化方法仍然是以离线训练范式为主,科研人员收集人类标注进行监督微调,或在训练时构建模拟环境进行强化学习。模型部署后变为静态成品,这一模式在实际应用中暴露出两个问题:
- 性能上限由离线训练数据决定:大语言模型的优化依赖有监督微调或在训练时构建的模拟环境中进行强化学习,模型性能受限于部署前构建的数据集和模拟环境,无法覆盖现实世界的多样性和动态性。
- 部署后的经验不能被使用:模型部署到真实场景后,会与用户或环境产生海量交互轨迹,这些轨迹包含真实的任务反馈、失败模式和成功策略,但现有范式中这些宝贵的经验数据被直接丢弃,模型无法从现实交互中学习,形成“训练即终点”的固化状态。
而大模型的在线学习方法之所以难以落地,是因为两大技术障碍,一是服务端无法访问用户侧的真实环境,因为用户环境中各异的系统函数、工具调用、用户数据等,无法在服务端一一构造;二是强化学习算法需要环境提供奖励,但现实交互往往只能提供文本反馈,为每个用户场景构建奖励模型也不具备工程可行性。
这些问题催生了对新学习范式的迫切需求,需要一种能够仅从原始文本经验中提取有用训练信号的方法,且无需服务端的环境访问或奖励监督。这就是微软亚洲研究院所提出的OEL在线经验学习所解决的问题。
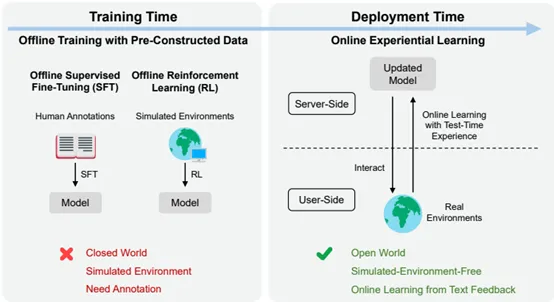
图1:离线训练与OEL在线经验学习。
左图:主流的离线范式在服务端利用人工标注(SFT)或模拟强化学习环境(RL)对模型进行训练,在预先构建数据的封闭环境中运行。右图:OEL在部署过程中形成良性循环。模型在用户端与真实环境交互,并将由此产生的测试时交互轨迹用于更新服务端的模型,无需标注,无需模拟环境,并能通过文本反馈实现开放世界学习。
OEL的创新:AI如何实现从经验积累到智慧内化?
OEL框架的创新在于,它试图在模型与真实世界的交互闭环中,建立一套自动化、无需人类干预的自我进化机制。它不仅是对算法的优化,更是对智能进化本质的重新定义——让AI从一个博览群书的学者,晋升为一个在实践中磨砺的行动者。
OEL框架之所以能够实现边做边学,关键在于一套严密的双阶段迭代逻辑:经验提取与经验整合。这类似于人类学习的过程,先通过复盘总结出避坑指南,再通过刻意练习将指南内化为肌肉记忆。
第一阶段:经验知识提取,将原始交互轨迹转化为可迁移的经验知识。从部署期间收集的交互轨迹中提取可迁移的经验知识,跨多个回合积累洞察。具体而言,当语言模型部署到用户侧环境并完成交互后,便能收集到一组交互轨迹。提取过程以累积方式进行,处理当前轨迹时,以模型自身作为提取器,将先前积累的经验知识与当前轨迹提取的知识拼接整合,实现知识的持续累积。
第二阶段:经验知识整合,通过同策略上下文蒸馏(On-Policy Context Distillation)实现认知内化。通过同策略上下文蒸馏将积累的知识内化到模型参数中,是OEL的技术核心。首先将交互轨迹在模型生成处切开构造前缀,让模型基于前缀进行单轮生成,这样无需进行环境调用,避免访问用户环境;然后再通过反向KL散度蒸馏一个带有经验知识的教师模型,从而将经验知识内化,无需在推理时提供知识上下文。
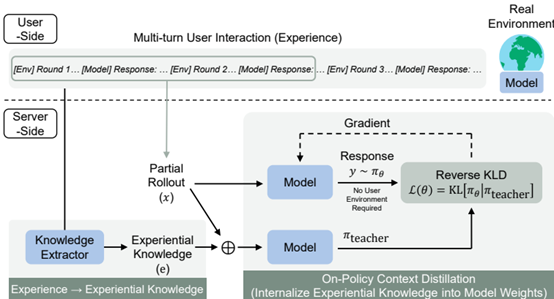
图2:OEL 框架整体流程。
在服务端,首先从收集到的轨迹中提取可迁移的经验知识,然后通过同策略上下文蒸馏将其整合为模型权重。在训练过程中,模型基于部分前缀(Partial Rollout)进行单轮生成,并通过反向KL散度蒸馏带有经验知识的教师模型,从而无需访问用户端环境。整个过程完全依赖于文本环境反馈,无需奖励模型或可验证的奖励。
这种提取-整合的循环往复,构成了OEL的在线进化引擎。每一轮迭代后,模型都会带着更强大的参数回到环境中收集更高质量的轨迹,从而形成一个正向反馈的螺旋,不断推高智能的上限。
实战结果:从文本游戏到高效学习的蜕变
为了验证OEL框架的有效性,研究员们在基于文本的游戏环境中进行了全面实验,涵盖不同模型规模,以及具备推理能力的思考型模型、无推理能力的非思考型模型两类变体。
实验在Frozen Lake和Sokoban两个文本游戏环境中进行,均基于TextArena实现。Frozen Lake中,智能体在网格中寻找目标位置同时避开空洞;Sokoban是空间推理谜题,要求模型将箱子推到目标位置。游戏不提供明确规则,模型必须通过探索发现它们。
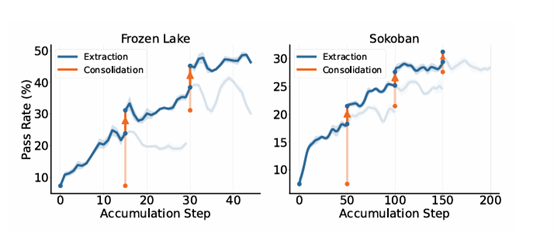
图3:通过反复迭代OEL模型的经验知识提取与整合阶段,该模型能够逐步提高通过率,从而实现在线学习。
实验结果:
在线学习,持续性能提升:随着 OEL 迭代轮数的增加,模型的任务通过率呈现出明显的阶梯式增长。 在Sokoban这个极考验空间逻辑的游戏中,模型经过几轮在线经验学习后变得很“老练”。
推理效率显著加快:在处理相同难度的任务时,模型不再需要冗长的自言自语,而是能够直击要害。在测试中,模型生成答案所需的token数降低了约30%,这意味着 AI 不仅变聪明了,而且变干练了,它可能不需要反复推敲尝试,而是能“一眼看穿本质”。
避免灾难遗忘:在传统异策略(Off-Policy)学习中,新知识的注入往往会导致旧知识的灾难性遗忘。研究员们在通用测试集如 IF-Eval上测试了进化后的模型,发现其通用指令遵循能力几乎没有受损。这得益于其独特的同策略上下文蒸馏机制,同策略(On-Policy)确保了在吸收新经验的同时,不破坏原有的知识结构。这一特性让模型兼具了专才和通才的能力,既能在专项任务上不断突破,又能保持原本的通用能力,更适配现实世界中多任务混合的场景。
此外,OEL 框架对于不同模型尺寸、推理模型/非推理模型都有性能提升,且性能增益在不同模型中具有一致性。
在线经验学习推动大模型进入新阶段
微软亚洲研究院提出的在线经验学习OEL框架,标志着人工智能发展进入了一个新阶段。传统的”训练-部署”范式正在被”部署-进化”的新范式所取代。真实世界部署不再只是训练的终点,而成为持续学习进化的起点。
OEL的提出证明了,通过提取可迁移的经验知识,并借助同策略上下文蒸馏将其内化到模型参数中,语言模型确实能够从自身的部署经验中持续改进。这为构建真正具有终身学习能力的人工智能系统提供了可行路径。
随着技术的不断成熟和应用场景的拓展,在线经验学习有望成为下一代人工智能系统的核心能力,推动AI从执行预定任务的工具,转变为能够适应环境、从经验中学习、持续自我完善的智能伙伴。这一转变将进一步影响人机协作的方式,重塑技术在社会中的角色,为人工智能的未来发展开辟新的可能。



