

慢,越来越慢…… 你在使用大模型时是否也面临这样的无奈:AI的回答总是需要等待,敲完一个问题,要等上几秒甚至十几秒才能得到回复,在复杂推理、多轮对话或代码生成等场景中,可能还需要更长的时间。
推测解码方法一定程度上缓解了这一延迟问题。它通过引入一个更快、更小的草稿模型,先猜一些可能的词元(token),再由大的目标模型统一验证,从而减少逐步生成的时间。然而,其现实效果并不总是理想的。由于推测解码采用固定策略或简单的启发式规则,所以无法根据具体任务动态调整生成多少和验证多少词。小模型猜得太多,大模型验证成本就会更高;小模型猜得太少,又无法发挥并行验证的优势。结果就是加速效果打折,甚至出现越优化越慢的情况。
在这样的背景下,微软亚洲研究院与北京大学联合提出了LTD(Learning to Draft)方法,它不再依赖静态规则,而是通过强化学习,让小模型生成和大模型验证之间形成动态协同关系,并直接以大模型的有效吞吐量为优化目标,助力大模型推理从机械加速走向智能加速。相关论文已被ICLR 2026接收。
点击文末相关链接,了解更多技术详情。
LTD:让小模型和大模型实现“灵魂契合”
传统的推测解码原理是“小模型猜词、大模型验证”。小模型用固定的长度去猜,比如每次固定猜8个token,然后大模型会一次性验证这8个token。但在简单的上下文场景中,小模型能猜对超过8个token,所以只猜8个会不够用,因为它其实可以猜更多;而在复杂的上下文终,小模型往往一个token都猜不对,如果猜8个然后送去验证的话,就会造成算力的浪费。另外,小模型和大模型在整个过程中就像两个没有沟通的人各干各的,没有配合。
LTD打破了这种各自为战的模式,将“单位时间有效生成量”作为唯一的优化目标,不再单纯追求猜中多少答案,而是看在猜token和验证的总时间里,能生成多少有效的正确内容,让小模型的生成阶段和大模型的验证阶段实现动态协同工作,从根本上实现智能加速。
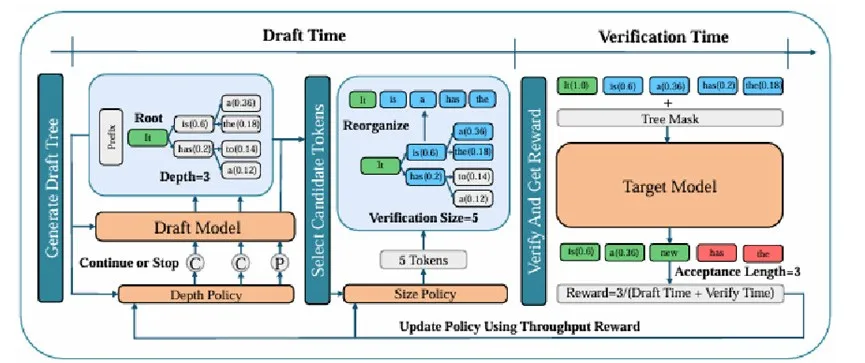
为了让猜token和验证环节精准适配、默契配合,LTD 为大模型的加速过程配备了两个“智能协调员”:深度策略和规模策略。
首先,深度策略管控小模型,决定小模型应该猜多少token,也就是草稿树的深度。它会根据当前的问题上下文、小模型猜测token的概率等信息,判断问题的难易程度,在草稿树每一层扩展后,做出“继续扩展”或“停止扩展”的二元决策,确保小模型的猜测数量恰到好处,既不会太少,浪费了大模型的验证能力,也不会太多而增加无谓的时间成本。
其次,规模策略专门对接大模型,决定大模型需要验证多少个候选答案,也就是验证规模。它会根据小模型猜测token的结果、当前的生成进度,从所有候选token中挑选出最优的数量让大模型验证,让大模型的每一次计算都能发挥最大价值。
两个策略通过强化学习联合优化,根据上下文与候选质量动态调整,实现协同平衡,使系统能够在不同输入和场景下自动找到最优平衡点,实现算力的高效利用。
更关键的是,这种默契是通过强化学习训练而来的。LTD 将整个推理过程建模为一个决策环境,每一轮“生成+验证”都会产生一个反馈信号。两个策略利用这一信号不断优化自身行为,逐渐学会如何协同决策。
其训练过程分为两个阶段。第一阶段,深度策略和规模策略分别独立训练。深度策略会在固定验证规模的前提下,反复训练如何根据不同场景判断最优的猜token深度;规模策略则会在固定猜token深度的前提下,训练如何选择最合理的验证规模。经过这一阶段的训练,两个协调员都能形成稳定的独立决策能力,从而为后续的协同配合打下基础。
第二阶段是迭代协同优化,让两个模型开始练习配合的默契。这一阶段先固定深度策略的决策规则,训练规模策略如何根据小模型的猜token结果,做出最适配的验证决策;再固定规模策略的决策规则,训练深度策略如何配合大模型的验证能力,调整最优的猜token深度。研究员们发现,仅需两轮交替迭代,两个策略即可实现完美的协同配合,让整个加速过程高效且顺畅。
这样的创新设计,让 LTD 方法拥有了三大优势。其一是时间感知能力。小模型不再盲目追求猜中答案的数量,而是始终在计算“是否值得”,从而避免无效开销。其二是动态适配能力,在不同任务、不同上下文中,系统都会自动调整策略,而不是依赖固定参数。最后是轻量高效,两个策略模型本身非常小,额外计算开销低于1.5%,几乎不会增加系统负担,这让加速方案的落地变得简单可行。
LTD 的加速实力超能“打”:最高提速 36.4%
研究员们在多个主流大模型,包括Llama-3、Vicuna、Qwen3 等,以及涵盖多轮对话 MT-bench、数学推理 GSM8K、指令遵循 Alpaca 等不同性质的基准测试集上,对 LTD 进行了全面评估。
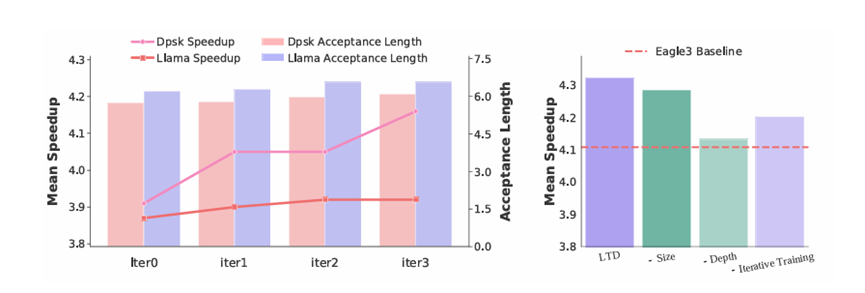
实验结果表明,LTD 在各种模型上都实现了稳健的提速。相比先进的 Eagle3 方案,Qwen3-32B 模型加速提升了高达 36.4%。在处理像DeepSeek这类擅长生成逻辑缜密、长思考链内容的模型时,LTD 也能带来大概10%的额外加速,这对于改善长文本生成模型的用户体验至关重要。
除了效率外,LTD 还展现出强大的鲁棒性和通用性。很多动态加速方法在面对高随机性任务时会失灵,甚至导致速度倒退,但 LTD 依然能维持约 5% 的提速优势。这意味着无论用户是在写一段代码,还是在进行创作,LTD 都能提供稳定的加速支持。
此外,LTD落地门槛极低。它不依赖对大模型结构的修改,可直接集成到现有推理框架中。由于策略模型十分轻量,部署成本接近于零,几乎可以无缝应用于现有系统,为企业和开发者提供了极具性价比的加速方案。
“时间感知”将成为大模型的加速度
LTD的创新不仅为大模型推理安上了加速键,还颠覆了推测解码“以猜对数量为目标”的传统范式,证明了优化中间指标不等于优化最终效果,加速必须时间感知。这意味着来自于系统层面的动态协同优化更有助于模型效率的提升。而LTD通过将强化学习与推理加速深度融合,为大模型自适应推理研究提供了一条新路径,将推动大模型从静态调参向智能调度转变。
与此同时,在算力成本越来越昂贵的当下,推理效率的提升相当于资源利用率的提高,也就是说同样的硬件可以支撑更多请求,或者在更低配置下实现相近性能。这不仅降低了企业部署大模型的门槛,更为大规模应用打开了空间,使大模型从实验室走向真实业务场景的路径更加清晰可行。
Learning To Draft: Adaptive Speculative Decoding with Reinforcement Learning
论文链接:https://openreview.net/pdf?id=IK9cbzzXLt (opens in new tab)